
【対談】機械翻訳活用時に必要な視点①機械翻訳でできることとできないこと
「TOEIC900点以上の精度」や「90%~の翻訳精度」。機械翻訳の精度を示す表現は多岐にわたっている。機械翻訳の精度は向上し、利用頻度も増えていることは業界でも明らかだが、「機械翻訳はまだ人の翻訳にかなわない」というのが翻訳業界の通説である。
人手の翻訳でできることと機械にできることの違いをよく理解し、分野や用途に応じて柔軟に機械を活用することが望ましいが、その判断のポイントはどこにあるのだろうか。
機械翻訳を活用する側の立場で、自らツールの開発にも携わり、お客様から様々な要望に応えているエヌ・アイ・ティー株式会社の代表取締役社長、新田順也さんをお招きし、機械翻訳との付き合い方、活用時に理解しておくべき重要なポイントについて意見交換をさせていただいた。
目次
機械翻訳でできることとできないこと
森口:
今日はよろしくお願いいたします。早速ですが、機械翻訳 (Machine Translation: MT) の精度を示す表現が巷には出ています。機械翻訳の精度というのはどんどん向上しており、特にニューラルネットに変わってから流暢性が増したことで、昔いわれていたような「文字を置き換えるだけの機械翻訳調」ではなくなりました。これによって、機械翻訳利用者の認知できる精度も高くなっていて、ビジネスの世界では、機械翻訳を使うべきじゃないかという話は当然増えてきています。
でも、我々の業界では、様々な検証や経験を経て、機械による翻訳結果は、プロの翻訳者による翻訳の代わりにはならないということは共通の認識となっていると思います。その点について、新田さんはどう思われますか。
新田:
両方そうだなと思っています。両方というのは、機械翻訳の精度も上がってきているので使えるようになってきています。でも、まだまだだなというのはあります。機械翻訳の用途によって機械翻訳の評価が変わると思います。
例えば外資系企業に勤めている私の友人によると、社内で機械翻訳を日常的に使っているそうなんです。英語の母語話者の同僚に、社内の日本語の議事録を機械翻訳で英語にしたものを読んでもらって、それを元に疑問があるところだけ質問を受けるんだそうです。
機械翻訳の下訳を活用して埋め合わせをすることによってコミュニケーションがすごく円滑になったし、そこのコストが削減できているし、スピーディーにもなった。と、もうかなり使えていますというのがその現場での声なんです。
また、機械翻訳を活用して論文の内容を確認するとか、発明者が海外の発明の内容を調査するというのはもう当たり前にやっていると思います。私はグーグルのニューラル機械翻訳が話題になる以前からこうした活用方法については友人から聞いていました。なので、機械翻訳の性能が上がった今では、「機械翻訳が現場では活用されてきているだろうな」と思っています。
かといって、特許翻訳の分野で、完全に出願できるまでの精度に機械翻訳はいくかというと、それは全然ダメです。ダメというのは、機械翻訳では、「発明が何なのか」とか「どの範囲の権利を守りたいのか」などが考慮されずに訳文が出力されているところが問題です。

意思のない訳文が出力されているので一貫性がなく、権利を守るための技術文書や契約書になりえないのです。表記上のことで言うと、用語の統一や正確性が担保できなかったり、数字が間違ってしまったり。そういうものも含め、やはりまだまだ難しいです。特許では図面にも情報が含まれており、その解釈も訳文の作成上は必要になります。特許法や審査基準の理解も翻訳で必要です。テキストの中にすべての情報が入っているわけではないのです。
また、そもそも原文がわかりづらくて解釈が難しかったり、日本語から英語への翻訳だと主語が欠けていることなど機械翻訳をするうえでいろいろな問題がありますので、そういうことを勘案していくと、どうしても百点にはなりません。やはり、人間が修正しなければならないのです。それをプロの翻訳者が一言で表現すると、「やっぱりまだまだだよね」と。もうそのとおりだと思います。
私自身が特許翻訳をやっていたので特許翻訳と言いましたが、法務翻訳や医薬翻訳などほかの分野の文書においても、文書の用途によっては機械翻訳だけでは当然まだ足りません。もちろん、誤訳を修正して正しい訳文にできるのであればこのような分野でも機械翻訳が使えると思います。
私はどんな文書であっても、軽率に機械翻訳が使える/使えないとは言い切りたくないんです。正確に説明しようとすると、分野や用途、言語方向といった条件がたくさん出てきてしまいますね(笑)。とにかく、現状では機械翻訳である程度意味をとらえた訳文が出力されるので、行間を読み誤訳を判断できる人が読む分には使えると思います。
森口:
それは、その人にとっては、翻訳のニーズは目に見える形であるのだけれど、予算や時間など制約があって、その限られた制約の中で出す質としてはどうか、ということを自ら評価できているという状態ですね。「この条件でこの質ならばぜんぜんオッケーだよね」と。こういうところでは、どんどん機械翻訳を使っていったらいいんじゃないかということですね。
新田:
そうです。
2009年から2019年の間の言語サービス市場の成長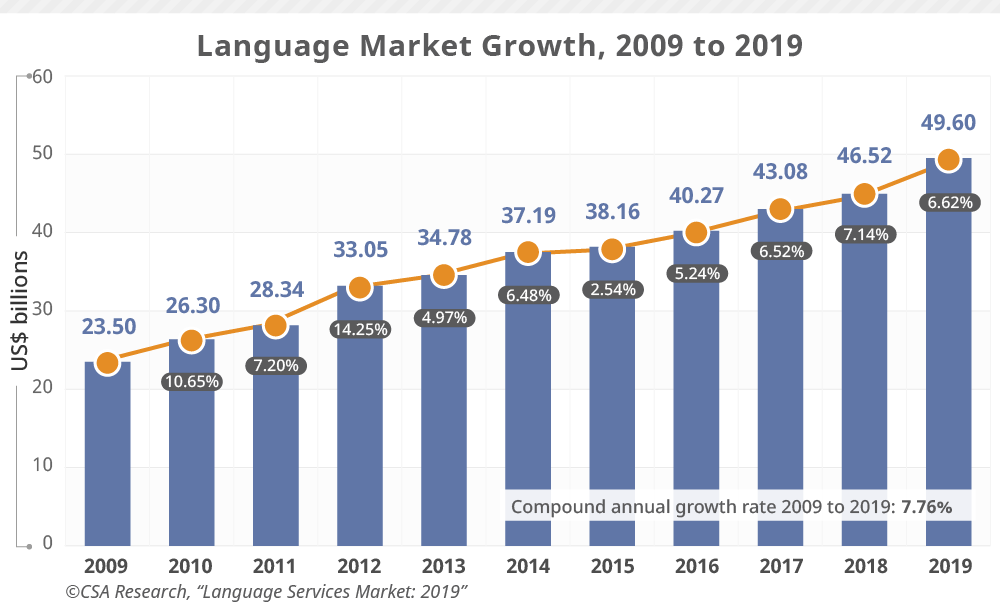
画像出典:The Largest Language Service Providers: 2019
森口:
翻訳の市場自体も2009年から2019年の間にほぼ倍ぐらいの市場規模に変わっていっています(画像出典:Common Sense Advisory)。これ以降も年平均6~7パーセントぐらいで市場が成長していくと予測されていて、過去10年もそうでした。どんどん翻訳対象テキストのボリュームも増えていっているんですが、本当に実力のあるプロの翻訳者さんの数は非常に限られていて、その人たちは、倍になったりしないんです。当然、処理できる量も限られてしまいます。
それでは、残った部分のギャップをどう埋めるかというと、やはり機械翻訳を活用しようという発想になると思います。そこは、使わないことには解決ができないギャップかなと思います。そのギャップの中には、機械翻訳の結果だけでは不十分なので、なるべく機械翻訳を活かしつつ、人が機械の誤りを修正するポストエディットというソリューションも存在します。
いずれにせよ、ギャップを全部が埋めるためにいちばん大事なのは、お客様側で「この条件でこの質ならばぜんぜんオッケーだよね」というシチュエーションをなるべく近くで実感してもらうことかなと思います。
これは我々のような翻訳会社の目線で見ると、仕様を確定する作業ですね。そうすると、機械翻訳でよいケースもあれば、決められた用語だけ直すといった工程を入れたらどうですかとか、最初からプロの翻訳者がやったほうがいいですとか、それぞれ用途を分けて提案していける感じがします。
新田:
それはありますね。
機械翻訳でできることとできないこと

森口:
新田さんは、いま、機械翻訳を活用されているんでしょうか。
新田:
使うものは使っています。
森口:
使うものと使わないものはどうやって分けているんでしょうか。
新田:
使うものというか、「使う文章」はということですかね。私はツール開発者なので、自分が開発しているツールの性能のアップのために自分のツールで翻訳したいんです(笑)。なので、基本は自分のツールで機械翻訳をできるかぎり活用したいと思っています。
ただ、すべての文章をツールで処理するかというとそうではなくて、機械翻訳の出力が意味をなさない個所は自分で翻訳します。同じ案件内でも、文章によって機械翻訳を活用するかどうかを変えてもいます。
森口:
当然のことながら、ツールを自分で開発しているということは機械翻訳だけではどうにもならない部分があるということですね。
新田:
そうです。いろいろな意味で機械翻訳の訳文が使いづらいことがあります。そのため全部書き直すとか、一部だけ使うとか、そういう使い分けをします。
森口:
いまのNMT(ニューラルネットワークの機械翻訳)ではできないこと、よくありがちなエラーというのをあらためて言うと、どういう部分でしょうか。
新田:
表記上のエラーで言うと、用語が統一されないとか、数字を間違えるとか、英日翻訳でいうと文末の「だ・である調」と「です・ます調」が混在するなどが挙げられます。不自然なカタカナの訳語も出力されたりします。内容のエラーとしては、文章が途中で切れてるような訳文が出力されたりします。現在の機械翻訳では文脈が考慮されないので、ぜんぜん違う意味になった訳文が出力されることもあります。
森口:
語彙的な結束性もあれば文法的な結束性もあると。
新田:
専門的な言い方はよくわからないのですが、文脈を無視した表現になってしまうというか、つながりがわかりづらい文章が連なってしまうことはよくありますね。たとえば、英文で「wax model」が説明されているとします。「wax model」は「蝋人形」の意味です。この次の文で「the model」と書かれている場合に、和訳で「モデル」という訳語が出力されるんです。
日本語で「モデル」って言うと「蝋人形のモデルになった人」や「写真のモデル」を連想するじゃないですか。でも文脈から判断すると「the model」は「その蝋人形」という意味なんです。だから「モデル」だと誤訳ですよね。こういう結束性が機械翻訳ではまだ対応できていません。で、「モデル」と出てきたときに、訳文を直せるのかという問題もありまして…。場合によっては、「モデル」でなんとなく読めてしまうときがあるからなんです。
実は、機械翻訳のエラーの話だけでなく修正の話にまで踏み込むと、機械翻訳のエラーと、それをポストエディターが直せるかどうかという翻訳者の能力によるエラーと、両方混在しちゃう感じがしています。
つまりポストエディットの訳文の品質が低いと評価された場合、機械翻訳のエンジンの性能が原因なのか、それともポストエディターの能力が原因なのか、もしくは発注条件による制限で修正する時間がなかったからなのかわからないですね、ということです。
森口:
一応、読者の皆さんのために説明しておくと、ポストエディターというのは機械翻訳の出力を直す作業を担当する人のことです。いま、話の中で「ポストエディター」と「翻訳者」というのが混ざっていますが、どうしてでしょう?
新田:
そうでしたね。そこも最近、自分の中でも定義が悩ましいところです。たぶん業界でもはっきりしていないのではないでしょうか。私は、機械翻訳の誤訳を修正するためには翻訳者の力が必要だと思っているので、機械翻訳の出力を直す作業者は翻訳者がいいと思っています。
私は機械翻訳を部分的に使って翻訳をした場合でも、最終的な訳文は自分の訳文だと思っているので、自分は翻訳者であると思っているんです。

森口:
いまおっしゃったように、機械翻訳を活用しようがしまいが、最終的に出す成果物の品質は自分が責任をもつという感覚でいくと、それってやっぱり自分の翻訳の結果というふうにつながります。ですから、ポストエディットというサービスというか、プロセスはあるとしても、ポストエディターというのはほんとうにいるのかなと、そういう職はあるのかなということですよね。
新田:
そのとおりです。私もこの「ポストエディター」という言葉が何なんだろうかと、少し違和感を持っています。
森口:
当社ではポストエディターをたくさん募集していますから、「お前の会社で募集してるのだからわかるはずじゃない」という話になってしまうのですが、作業の内容を描写するという意味ではポストエディットなので、それをやる作業者はポストエディターでいいんですよね。ただ、それが専門的な職業かといわれると、たぶん違うと思うということです。
新田:
そう思います。とある媒体の記者さんとの会話の中で、「ポストエディター」はこのAI時代に新しく生まれた職業であるというような話になっていて、「あれ、それって職業かな」と思ったことがあります。
ポストエディターを職業ととらえる流れは、過渡期のいま発生しているだけで、将来的にはなくなるんじゃないかなと考えてもいます。職業ではなく翻訳プロセスの中で使用される機能や役割として表現しているだけではないのでしょうか。CATツールを使う人には翻訳者以外の職業名が付いていないわけですよね。だってその人はCATツールを使った翻訳者ですから。
森口:
確かに、「CATツールユーザー」とはいうかもしれませんが職業ではないですね。
新田:
ですよね。職業は翻訳者であり、そこに「こういうCATツールを使っています」ということです。ですから、機械翻訳をポストエディットする場合も翻訳者がプロセスの一部として機械翻訳を使っているだけという認識になってくるともう少し違うだろうと思います。

<②に続く>





%E3%81%AE%E9%87%8D%E8%A6%81%E6%80%A7-%E4%BD%9C%E6%A5%AD%E5%8A%B9%E7%8E%87%E3%82%92%E5%90%91%E4%B8%8A%E3%81%95%E3%81%9B%E3%82%8B%E6%96%B9%E6%B3%95.png?width=900&height=600&name=%E7%BF%BB%E8%A8%B3%E5%89%8D%E5%87%A6%E7%90%86(%E3%83%97%E3%83%AC%E3%82%A8%E3%83%87%E3%82%A3%E3%83%83%E3%83%88)%E3%81%AE%E9%87%8D%E8%A6%81%E6%80%A7-%E4%BD%9C%E6%A5%AD%E5%8A%B9%E7%8E%87%E3%82%92%E5%90%91%E4%B8%8A%E3%81%95%E3%81%9B%E3%82%8B%E6%96%B9%E6%B3%95.png)


