
memoQ 新機能“Regex Assistant”を検証!~正規表現を使った検索や置換をアシストする機能~
翻訳支援ツール memoQ 9.8で新しく実装されたRegex Assistant(日本語名:正規表現アシスタント)。エディタ上で、正規表現を使った検索や置換をアシストする機能ということですが、難解なイメージがある正規表現が手軽に使えるのならば、魅力的な機能ですね!
川村インターナショナルで日々memoQを使う筆者が、新機能を検証してみました。
正規表現とは?
Regex Assistantの検証を始める前に、「正規表現(英:regular expressions)」とはどのようなものなのか、説明します。正規表現とは、簡単にいうと文字列をパターンとして表現するための表記法です。
正規表現を使うと、文字のグループ(例えば、数字やアルファベット等)を特殊な文字を使ってまとめて表すことができます。Microsoft Word等でワイルドカードを使って検索をしたことがある方もいらっしゃると思いますが、正規表現はワイルドカードよりも更に表現できる文字列のバリエーションが増えたもの、というと分かりやすいかもしれません。
なぜ正規表現を使うと便利なの?
正規表現を使うと、ある特定のパターンに当てはまる文字列をまとめて表現することができます。例えば、電話番号090-xxxx-xxxxの形に当てはまる文字列をまとめて検索したり、ある特定の文字で始まる文字列(文頭にスペースがあったり、小文字になっている文字列など)をまとめて抽出することができます。他にも正規表現を使うとさまざまな文字列を表現できますので、翻訳の見直しや校正作業の効率をアップできます。
実際の作業事例
具体的にどのくらい便利なのかイメージが湧かないという方のために、筆者が担当した案件の中で、実際に役に立った場面をいくつか挙げたいと思います。
①資料番号が正しく訳されているか、チェック
マニュアル翻訳の案件で、大文字アルファベット2文字と数字6桁からなる資料番号が、仕様に沿って正しく置き換えられているかチェックする必要がありました。正規表現を使うと資料番号をパターンとして表現できるため、まとめて抽出できます。ひとつひとつ検索していく必要がないため、見落とす心配もありません。
②文頭の数字がスペルアウトされているか、チェック
ニュース記事の翻訳案件で、文頭の数字はスペルアウトするという仕様がありました。正規表現を使うと、文頭に数字がある文字列をまとめて抽出できるため、仕様違反の可能性がある箇所を素早く確認できます。
③文法ルールが守られているか、チェック
マニュアル翻訳の案件で、「現在進行形はできる限り使わない」という仕様がありました。こちらも、正規表現を使うとbe動詞 + ~ingの形になっている部分をまとめて抽出でき、全て読み返して確認するといった手間を省くことができます。
Regex Assistantとは?
正規表現を使うと、特定のパターンに当てはまる文字列をまとめて検索できるため、非常に便利であるということがお分かりいただけたと思います。ですが、正規表現になじみがないと、どのように正規表現を使ってパターンを表現すればよいのか分かりませんよね。memoQのRegex Assistantはそんな正規表現ビギナーでも、簡単に正規表現の作成ができてしまうツールのようです。
Regex Assistantを使ってみよう!
エディタ画面の歯車マークをクリックすると、フィルタリングオプションが表示されます。ここで[正規表現を使用]にチェックを入れます。
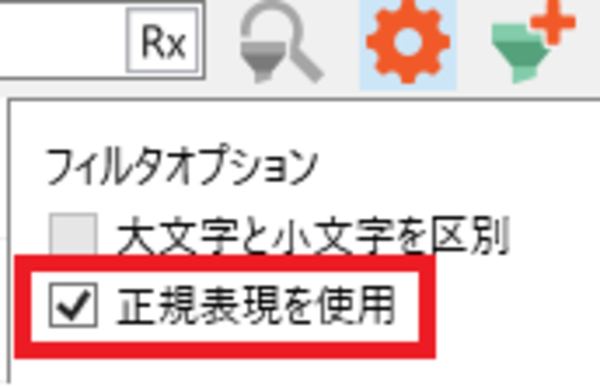
チェックを入れると、ソースおよびターゲットセグメント上部にある検索フィールドに[Rx]ボタンが表示されます。

[Rx]ボタンを押下すると、Regex Assistant画面が表示されます。
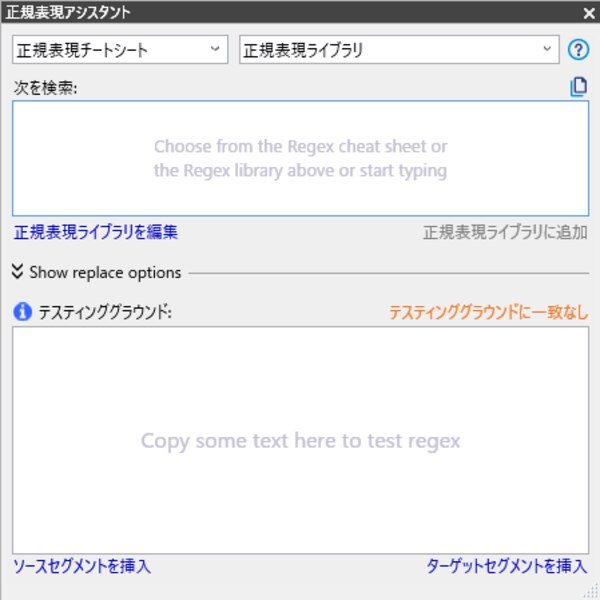
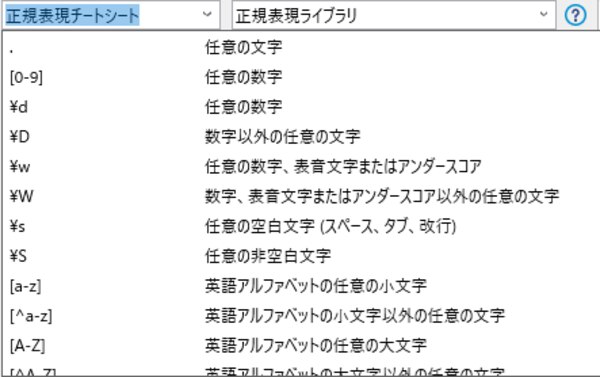
正規表現チートシート
正規表現チートシートドロップダウンでは、特殊文字(正規表現)が意味とともに一覧になっていますので、正規表現の知識がない人でもこちらから特殊文字を選択して正規表現を作成できるようになっています。
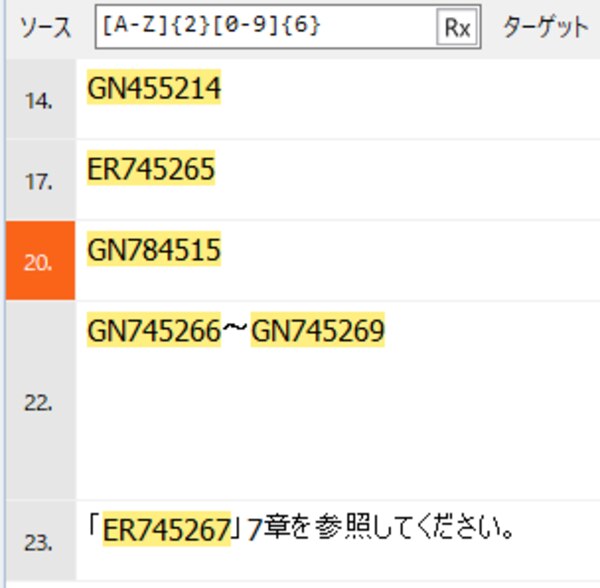
「実際の作業事例」で例に挙げたうちの一つ「大文字アルファベット2文字+半角数字6桁」からなる資料番号(AB123456の形式)を含むセグメントの抽出を、正規表現チートシートを使って行ってみたいと思います。
まずは、最初のアルファベット2文字を表現します。リストの中から「英語アルファベットの任意の大文字」を選びます。

次に文字数を表す正規表現を選びます。「厳密にn回出現」とある特殊文字を選びます。

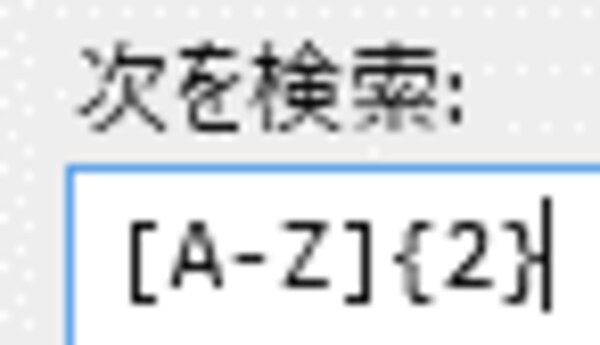
[次を検索:]フィールドに下記の通り正規表現が入力されるため、nの部分を”2”に置き換えると、「大文字アルファベット2文字」を表す正規表現ができました。
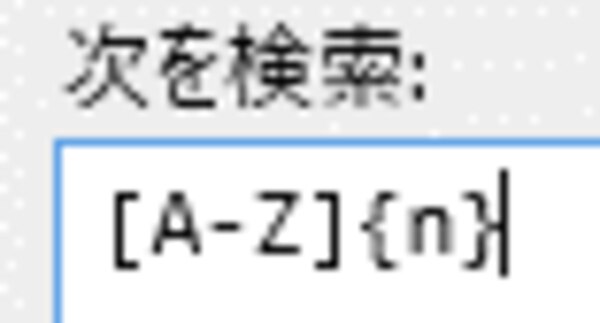 →
→ 
次に、同じ要領で、半角数字6桁を表す正規表現を選択します。

「任意の数字」を選択したら、次は桁数を指定します。{n}を選び、nを6に置き換えます。これで、正規表現ができました。
あとは、フィールド右上にあるコピーアイコンをクリックし、ソースセグメントまたはターゲットセグメント上部の検索フィールドにペーストし、エンターキーで検索することができます。

資料番号を含むセグメントが抽出されました。
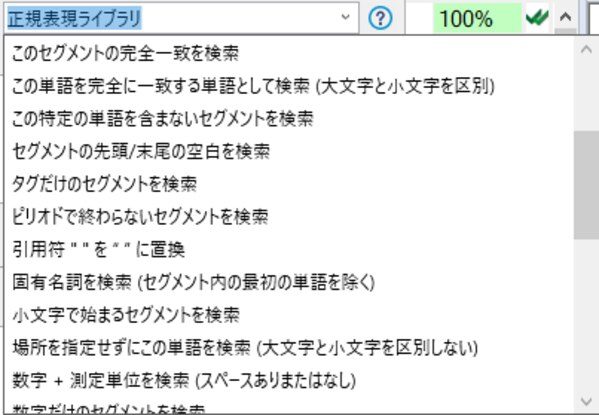
正規表現ライブラリ
正規表現ライブラリには翻訳・校正作業時に役に立ちそうな正規表現が一覧としてまとめられています。文頭の空白や小文字等、例として挙げたものもこちらにプリセットされているため、自ら作成する必要が無いのは嬉しいですね。自分で作成した正規表現をこちらに保存することもできるため、よく使う正規表現は毎回作成する手間が省けるようになっています。
まとめ
筆者は校正作業を行う際によく正規表現を使うのですが、正規表現に詳しいわけでは無く、毎回検索して調べるのが面倒だと感じていました。「正規表現チートシート」があると、都度調べる手間が省けます。
さらに、今回は紹介できませんでしたが、作成した正規表現が正しいかチェックできるテスティンググラウンドもあり、全てmemoQのエディタ上で済んでしまうため、かなり便利だと感じました。
Regex Assistantの中でもまだまだご紹介できてない機能があるため、次回続編としてご紹介できればと思います。
川村インターナショナルのサービス
川村インターナショナルでは、翻訳支援ツールを導入予定あるいは導入済みのお客様を対象とした「翻訳支援ツール導入支援」や、自社の情報資産を活用した「翻訳メモリ・用語集作成」などの翻訳業務効率化につながる「言語資産データ作成サービス」を提供しております。
機械翻訳の導入を検討している、翻訳業務を効率化したい、という方はお気軽にお問い合わせください。








