「翻訳を効率的に、かつコスト削減をしながらも、高い品質を保ちたい!」非現実的な要望にも見えますが、これを簡単に実現してくれるのが「翻訳メモリ」(TM)です。
翻訳メモリを使うと、過去の翻訳データを流用し、差分を翻訳するだけで翻訳が完結するため、納期の短縮とコスト削減を同時に実現できます。さらに、過去の訳文を参照しながら翻訳を進めることができるので、既存訳と用語や表現を合わせることも容易にでき、高い品質を維持することも可能です。
翻訳メモリの作成方法は前回の記事でご紹介しました(Xbenchを使ったTMの作り方)。前回の記事で紹介した方法は、原文と訳文が対訳の形式になった状態のファイルがあることを前提としていたので、もしも大量のWordファイルが日本語と英語でそれぞれ存在する場合、上記の方法は使えません。今回は、対訳形式になっていないデータを使って、イチからTMを作る方法をご紹介します。

アライメントとは?
アライメント(alignment)とは、英語で「一直線にすること」「整列すること」を意味し、翻訳業界では「原文と訳文が対比するように並べること」を指します。あらゆるCATツールで活用できる翻訳メモリを作成するためには、「アラインされた」原文と訳文の対訳データが必要です。
それでは、「アラインされた」対訳データはどのように作成するのでしょうか?
アラインの作業は手動でエクセルなどに原文と訳文を貼り付けて行うことも可能です。しかし、膨大な量の原文と訳文のデータがそれぞれ存在する場合、アライン作業を手動で行うと途方のない時間がかかってしまうこともあります。
このような作業はできるだけ自動化してしまいたいものです。完全な自動化はまだ難しいですが、memoQのアライメント機能を活用すると、大幅な自動化を行うことが可能です。
そこで今回は、memoQを使ったアライメントの方法をご紹介します。

*本作業ではCATツールのmemoQ 8.6を使用します。以前のバージョンにもアライメントの機能は備わっていますが、UIが多少異なる場合もありますのでご了承ください。
*以降のキャプチャでは、「日本法令外国語訳データベースシステム」よりダウンロードした法令の日本語版と英語版を、原文と訳文の対訳ファイルのサンプルとして使用しています。
手順①アライン用のファイルをmemoQにインポートする
1. まずは、レイアウトがある程度揃った原文データと訳文データをそれぞれ用意します。
2. memoQを立ち上げ、memoQダッシュボードの[プロジェクト]リボンから[新規プロジェクト]を選択し、新しいプロジェクトを作成します。(オンラインプロジェクトでも、ローカルプロジェクトでも、どちらでも構いません)
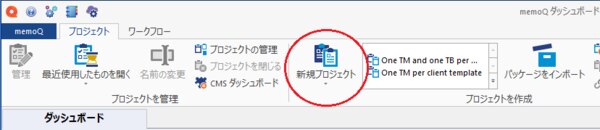
3. 新規memoQプロジェクトポップアップ画面が開かれるので、必要な情報を入力し、プロジェクトを作成します。新しく翻訳したい文書がある場合は翻訳文書を追加しますが、ない場合、つまりアライン作業のみを行いたい場合は追加せずに進めます。翻訳メモリと用語集に関しても同様です。
4. 新しいプロジェクトが作成できたら、プロジェクトホーム画面で[ライブ文書]をクリックし、[ライブ文書]リボンから[新規作成/使用]を選択し、空の資料を作成します。
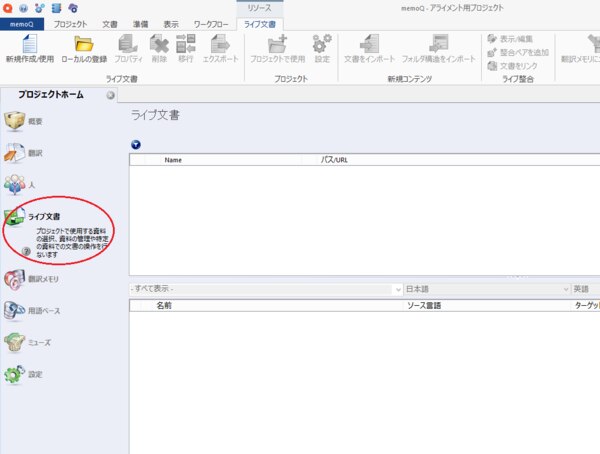
5. 空の資料ができたら、[整合ペアを追加]をクリックし、原文ファイルと訳文ファイルを追加します。
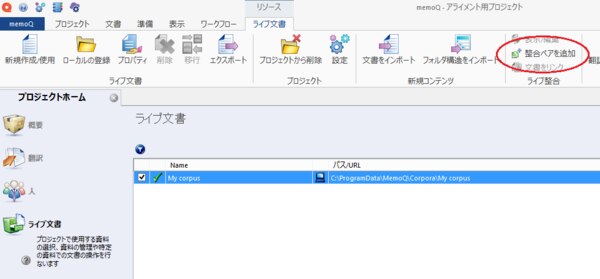
6. まずは、[ソース文書を追加]をクリックし、原文のファイルを追加します。
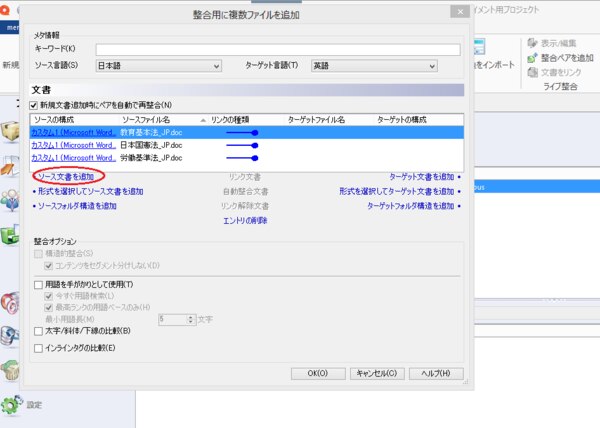
7. 次に[ターゲット文書追加]を選択し、訳文のファイルを追加します。ここで、原文と訳文のファイル名がある程度一致していれば、memoQによって自動的にソースとターゲットの文書がリンクされますが、memoQが識別できなかった場合は手動で文書ペアをリンクする必要があります。
手動でのリンク方法は、整合させたいドキュメントをそれぞれ選択し、[リンク文書]を選択します。
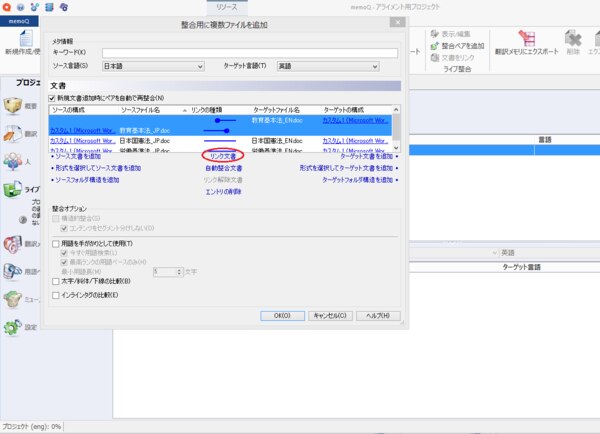
8. リンクが完了し、[OK]を押すと、memoQにドキュメントがペアになった状態で追加されます。
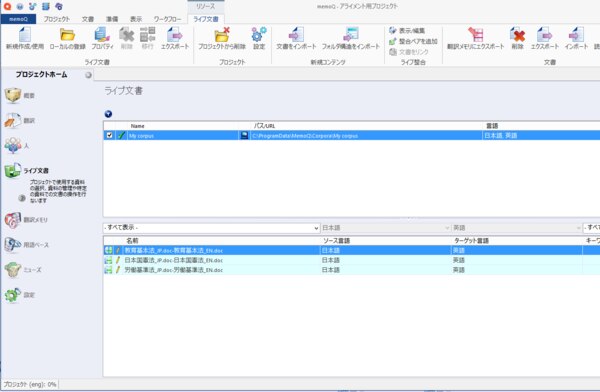
手順②memoQ上でアライン作業を行ってみる
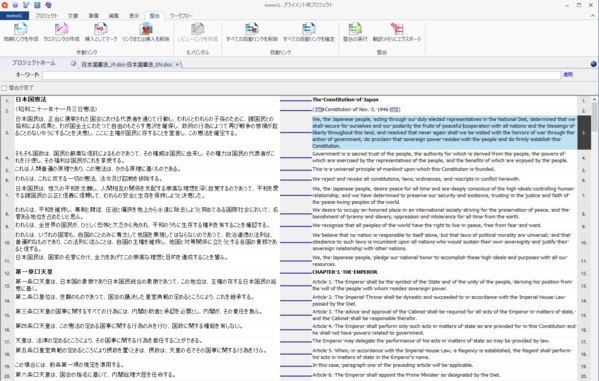
それでは、インポートされた原文/訳文ファイルのアライメントを行い、対訳データを作成してみましょう。
まずは、文書の一覧からアラインしたいファイルを選択し右クリックして[表示/編集]を選択します。アライン用編集画面が開かれるので、この画面上でアライン作業を行っていきます。
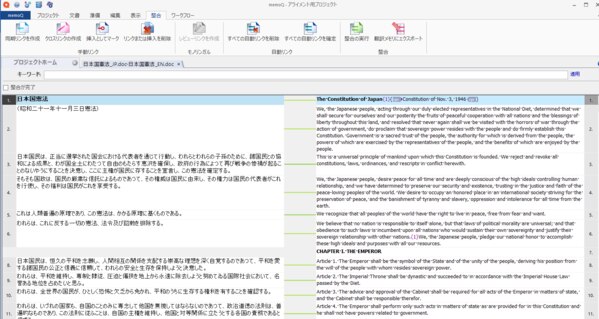
ファイルを開いた時点では、memoQによって、自動的に緑色の実線で整合された状態になっています。それぞれのリンクが正しく、手動で編集する必要がない場合はそのまま触らず、スルーします。
memoQによる自動リンクが正しくない場合は、セグメントを分割したり、結合したりして、リンクを整えていく必要があります。
以下に主な操作方法をピックアップしてみました。
◎セグメントを分割する場合
分割したい箇所にカーソルをあて、右クリックし[分割]を選択します。
複数の文が一つのセグメントにまとまってしまっている場合は、TMを作成するという側面から、文単位に分割してしまうことがおすすめされます。
◎セグメントを結合する場合
一文が複数のセグメントに分かれているなどの理由からセグメントを結合したい場合は、結合したいセグメントを複数選択し、右クリックで[結合]を押します。

◎リンクされていない原文と訳文をリンクさせる場合
リンクさせたいセグメントをそれぞれ選択し、右クリックで[同期リンクを作成]を選択します。
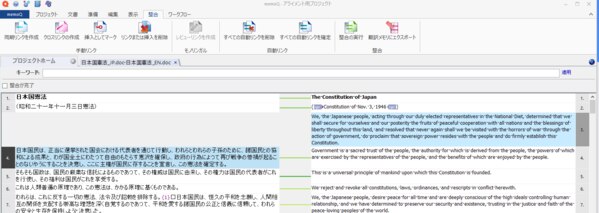
◎その他使える機能
[クロスリンクの作成]
異なるグリッド行にある二つのセグメントをリンクします。
[整合の実行]
memoQが自動で整合を実行します。memoQによって整合されたセグメントペアは緑色の線で表示されます。
[すべての自動リンクを確定]
memoQによって自動でリンクされた緑色の線を確定し、青色の実線に変更します。
上記の作業を繰り返し、対訳で整合が完了したら、左上の[整合が完了]チェックボックスにチェックを入れ、作業を完了します。
作った対訳データの活用法
作成した対訳データは、エクスポートすることによって、あらゆるCATツールでTMとして参照できるようになります。
◎memoQで参照する場合
作成した対訳データは、memoQで作成したTMへとエクスポートでき、memoQ上で翻訳を行う場合はそのままメモリとして参照することができます。エクスポート先のメモリが存在しない場合は、画面左の[翻訳メモリ]タブで新しいTMを作成することができます。
◎その他CATツールで参照する場合
対訳データを「.mqxlz」形式でエクスポートすることもできます。mqxlzファイルはXbenchを使えば簡単に「.tmx」形式にエクスポートできるので、その他のCATツールでTMとして参照したい場合はtmxファイルに変換してしまうことがおすすめされます。
おわりに
いかがでしたでしょうか。このようにして翻訳メモリを作成することにより、翻訳の大幅な効率化を図ることができます。アライメントを完全に自動化してしまうことはまだ難しいですが、ツールを活用することによってその手間は大幅に改善されます。TM作成の対応をしている翻訳会社は多数ありますので、ツールをもっていないが、TMを作成したい、という場合はぜひ翻訳会社に相談してみてください。
関連記事
フィードバックフォーム
当サイトで検証してほしいこと、記事にしてほしい題材などありましたら、
下のフィードバックフォームよりお気軽にお知らせ下さい!
例えば・・・
CATツールを自社に導入したいが、どれを選べばいいか分からないのでオススメを教えてほしい。
機械翻訳と人手翻訳、どちらを選ぶべきかわからない。
翻訳会社に提案された「用語集作成」ってどんなメリットがあるの?
ご意見ご要望をお待ちしております!
下のフィードバックフォームよりお気軽にお知らせ下さい!
例えば・・・
CATツールを自社に導入したいが、どれを選べばいいか分からないのでオススメを教えてほしい。
機械翻訳と人手翻訳、どちらを選ぶべきかわからない。
翻訳会社に提案された「用語集作成」ってどんなメリットがあるの?
ご意見ご要望をお待ちしております!
新着記事一覧



