翻訳が楽になる!
翻訳メモリを活用する
翻訳が楽になる!
翻訳メモリを活用する
「翻訳作業を効率化したい」この要望に応える方法として、1番に挙げられるものが「翻訳メモリ」(Translation Memory: TM)です。
翻訳メモリとは、文章を特定の2言語が対になった形式で保存したファイルです。複数のドキュメントの対訳を保存することもできますし、1文単位でも保存できます。対訳のデータをどんどん積み重ね、新たな翻訳が発生した際に既存訳を流用したり、過去の訳文を検索したりすることができます。
翻訳メモリは、これまでの対訳データを管理し、効率的に活用し、高い品質を保つうえで重要なアイテムとなります。

それでは、「翻訳メモリ」の実態はどのようなものなのでしょうか?
翻訳メモリは「Translation Memory Exchange」の規格で作成されたファイルで、拡張子は「.tmx」となっています。以前紹介したバイリンガルファイルと同じで、特定のツールを使用しないと、保存されたデータを参照したり、編集したりすることができません。(メモ帳でも開いて編集はできますが、タグがすべて表示された状態になりますため、編集しづらいです。)
主要なCATツール(Trados、memoQ、OmegaTなど)をお持ちであれば、tmxファイルをインポートすることによって編集や参照をすることができます。
それでは、翻訳メモリの作り方と、具体的にどのように活用して翻訳を簡単にすませることができるかをご紹介します。
翻訳メモリの作成方法はさまざまな種類がありますが、今回は前回紹介したXbenchとTradosを使用して作成します。
まずは対訳データの格納されたtmxファイルを作成します。
使用するものは以下のとおりです。
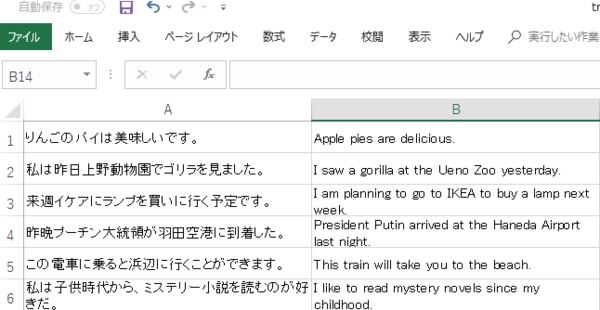
(このような形式になったファイルです。)
なお、本記事ではXbench 3.0を使用していますので、2.9とはインターフェイスが若干異なります。
それでは実際の手順をご紹介します。
① Xbenchを立ち上げ、対訳形式のExcelファイルを取り込む
[Project]タブから[New]をクリックすると、「Project Properties」ポップアップウィンドウが表示されるので、該当のExcelファイルをドラッグアンドドロップします。ファイル形式は[Tab-delimited Text]を選択し、[Ongoing translation]をチェックボックスにチェックを入れます。

これで、ExcelファイルのデータがXbenchにインポートされた状態になりました。
② インポートした対訳データをtmx形式で吐き出す
[Tools]タブで[Export Items...]をクリックします。
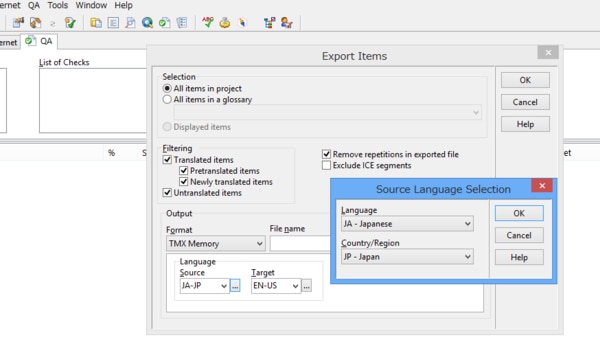
「Export Items」ウィンドウが開きますので、適宜カスタムの設定を行い、「Output」の「Format」を[TMX Memory]に設定してファイルをエクスポートします。
なお、この際に言語設定を行う必要があります。「Language」の「Source」(原文)「Target」(訳文)の真下にある[...]ボタンをクリックすると、それぞれの言語を設定することができます。ここでは「Language」(言語)と「Country/Region」(国/地域)を選択し、初めて言語設定を行うことができます。例えば、英語の場合、「Language」は[EN-English]になりますが、英語にもアメリカで話されている英語やイギリス、オーストラリアなど、国や地域によって変わってきますので、「Country/Region」を設定する必要があります。
使用する言語と国/地域を登録し、プルダウンから選択したら、エクスポートの準備完了です。保存先のパスを指定し、[OK]をクリックします。
そうすると、訳文データが保存されたtmxファイルが生成されます。
さて、せっかく作成したtmxファイルですが、どのようにして翻訳に利用するのでしょうか?
翻訳を翻訳会社に依頼する場合は、作成したtmxを依頼時に渡すと、翻訳会社が渡された対訳データを活用し、既存訳に準拠して案件を進めることができます。
しかし、せっかくなので、ここでは自社でtmxファイルを流用し、翻訳を進める方法をご紹介します。
必要なものは以下のとおりです。
① 空のsdltm(Tradosの翻訳メモリ)を作成する
まずは、Tradosを立ち上げ、[ファイル]タブで[新しい翻訳メモリ]を選択します。
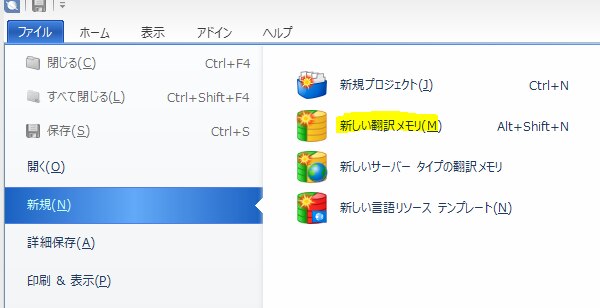
「新しい翻訳メモリ」ポップアップウィンドウが表示されますので、ファイル名やファイル保存先、そして原文と訳文を設定します。言語の設定は、先ほどtmxを作成する際にXbenchで登録した言語と同じになるようにしてください。適宜設定をし、メモリを作成します。

[閉じる]を押すと、翻訳メモリのウィンドウに切り替わり、先ほど作成した新しい翻訳メモリをTrados上で選択できるようになります。
② 空のsdltmにtmxの対訳データを流し込む
作成した翻訳メモリを右クリックし、[インポート]をクリックしてtmxの対訳データをインポートします。
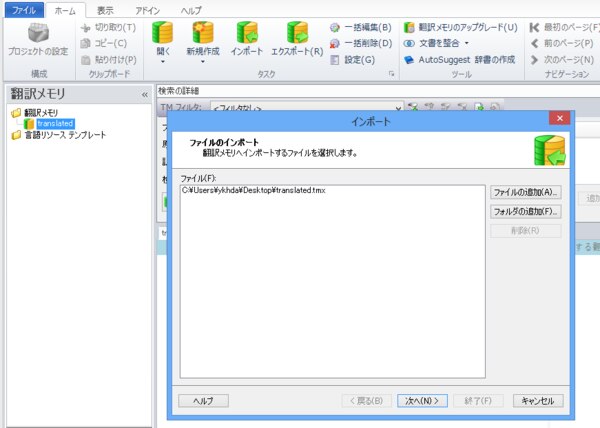
適宜設定をカスタマイズし、インポートを実行します。インポートが完了し、ポップアップ画面を閉じると、メモリに対訳データがインポートされたのが分かります。

これで「.sdltm」形式翻訳メモリが作成され、エクセルの対訳データがTradosでの翻訳に活用できるようになりました。
翻訳メモリができありましたので、次は翻訳対象のファイルを翻訳するためのプロジェクトを作成します。
[ホーム]タブから[新規プロジェクト]をクリックします。新しいプロジェクトを作成するウィンドウが開きますので、適宜設定をカスタマイズしながら進みます。こちらでも、言語設定はXbenchのものと一致するようにしてください。
「プロジェクトファイル」画面では[ファイルの追加]をクリックし、翻訳対象のファイルをインポートします。

次の「翻訳メモリと自動翻訳」の画面で、メモリを設定します。
[追加]から、[ファイル共有タイプの翻訳メモリ]をクリックし、先ほど作成したsdltmを開き、プロジェクトに追加します。

チェックボックスはデフォルトの設定のままで問題ないかと思います。これから新しく翻訳する文をメモリに登録したくない場合は、「更新」のチェックボックスを外すことをお勧めします。
プロジェクトの設定と作成が完了したら、翻訳対象のファイルをTradosで開いてみます。
エディタを開き、それぞれのセグメントにカーソルを充てると、メモリに登録された訳文が流用されます。

上記エディタで確認できるように、赤い差分箇所だけを新たに翻訳し変更すればよいので、翻訳を非常に楽に行うことができます!
いかがでしたでしょうか。翻訳メモリを活用すると、このように翻訳作業を効率化することができるのです。
今回はすでに原文と訳文がエクセルに並べられ、「対訳」の状態になった(=アラインされた)ファイルをtmxに変換して活用する方法をご紹介しました。アラインされていないファイル、つまりはドキュメントの日本語版ファイルと英語版ファイルが別々に存在し、それを対訳のメモリにしたい場合は、アラインをする必要があります(アライメント)。
一見手間がかかりそうな作業ですが、エクセルにマニュアルで対訳を張り付けていく必要はなく、ツールを使ってアライン作業を行うことができます。
次回はアライメントの方法についてご紹介いたします。