企業で翻訳に携われる方々にとって「用語集」は非常に関心の高いテーマです。こうしたニーズに応えるべく「用語集の利活用」をテーマにして連載記事をお届けしています。今回はその第五弾です。
第一弾、第二弾、第三弾、第四弾は次からお読みいただけます。
・第一弾:翻訳における用語集の利活用①
・第二弾:翻訳における用語集の利活用②バイリンガル用語集を自動的に作成する方法?
・第三弾:用語集データ管理ツールの選択ポイント
・第四弾:用語集に必要な項目と不要な項目
前回は、用語集構築時の基本方針として、用語集に含まれる情報項目と、対象エントリの範囲について紹介しました。今回は、用語集の運用時に心がけたいポイントを説明します。しっかりと作った用語集も、使い方を間違えると正しく適用できません。間違った使い方のほとんどは、コミュニケーションのミスから発生します。大きく分けて以下のようなコミュニケーションを事前に決めておくことが大切です。
どんなに用語集を整備しても、どんなに表記のルールを固めても、例外は発生します。翻訳をする部門が一生懸命基準を定めても、文書を作成しているオーナーや技術者は、そうした基準を理解していないことがほとんどです。想定外の事態や不明点が出た際に、関係者が質疑応答できる仕組みづくりをしておくことが重要です。これは、用語集の運用に限らず、翻訳プロジェクトで発生した不明点や報告事項を関係者間で共有できるため、とても重要な要素になります。
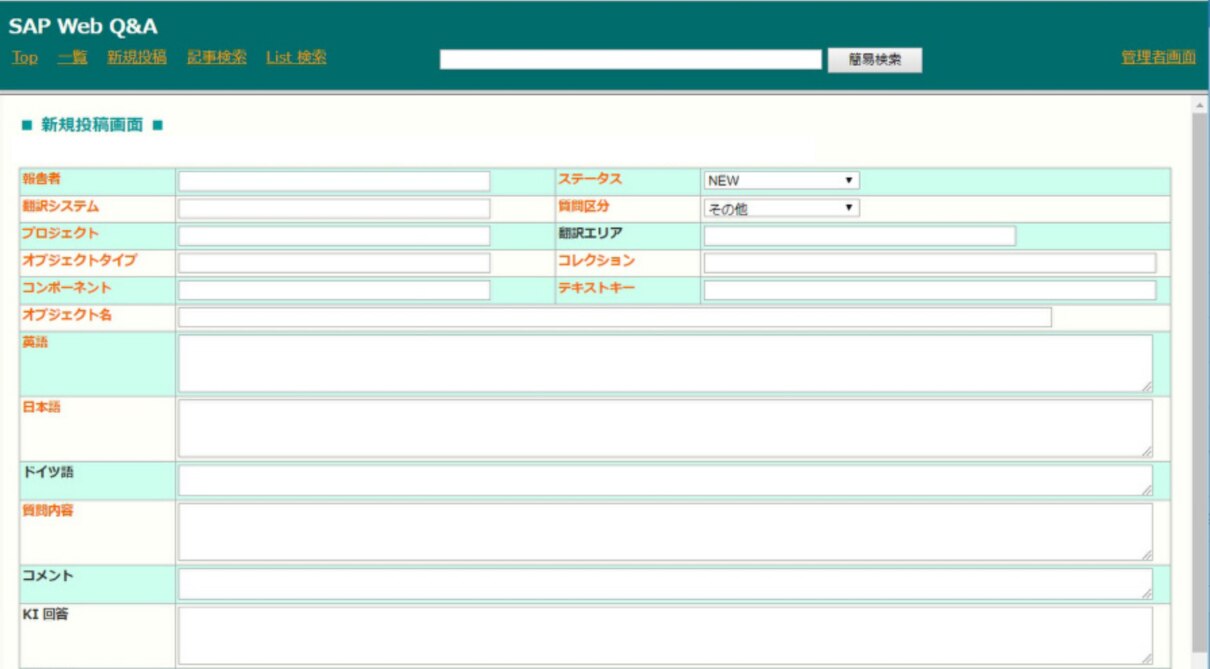
例えば、当社では以下のような自社開発したQ&Aツールを運用しています。
用語に関連するQ&Aのやり取りは、Webで実施するのが理想的です。なぜなら、
からです。すでに述べた通り、WebベースのQ&Aは用語集に限らず、翻訳プロジェクト内で出てきた不明点を解決するプラットフォームとしてはとても役立ちます。用語について不明点や矛盾が出てきた場合には、威力を発揮してくれるはずです。用語ライフサイクルを含む管理方針については、次回紹介します。
とはいえ、Q&Aのやり取りが少ないに越したことはありません。2.~4.は事前に決めておける運用ルールです。まず、2.の他の資料との優先順位について説明します。翻訳プロジェクトによっては、複数の種類の資料や用語集が提供されることも珍しくありません。また、翻訳メモリ(Translation Memory: TM)が提供されることもよくあります。用語集で定義されている単語と、TMの訳語が異なる場合は厄介です。というのも、単に過去の翻訳が間違っていたケースもあれば、顧客が意図的に用語集通りの訳し方にしないでほしいと表明しているケースもあるからです。こうしたケースの解決はどうすれば効率よくできるでしょうか。
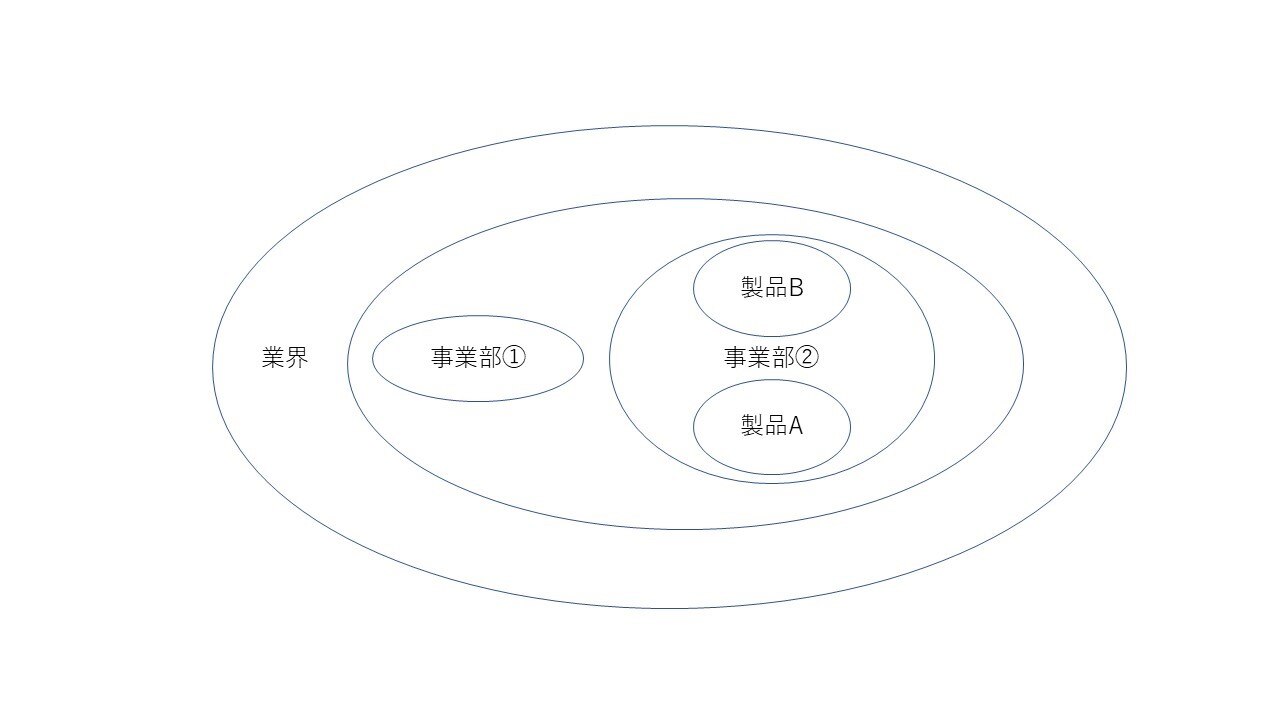
もう一つ、用語集の矛盾について説明しましょう。用語集が複数提供されている場合は、すでに述べたような、ピラミッド構造が形成されることもあれば、ネスト構造になっている場合もあります。
いずれの場合でも、どの条件下でどの階層(あるいはグループ)の用語を使用するかを事前に決めておくことが重要です。
たとえば上の図の場合、事業部①の用語集にはないが、事業部②の製品Bとして用語が登録されていたとします。ただし、自分が翻訳しているのが事業部①のプロジェクトだった場合に、これを適用してよいものでしょうか。同じ会社だからOKだというケースもあれば、用語によって事情が異なることもあるでしょう。作業者の側でも、用語の特殊性や固有性を考慮して、ある程度の判断をすることは可能かと思いますが、矛盾が発生した場合に、どの優先順位で用語選択をするかがあらかじめ決められていると翻訳作業者の業務効率が大幅に向上します。また、質問は前述したQ&Aを介して実施する旨を決めておけば、窓口も一元化されます。
ソフトウェアUIのローカリゼーションや、マニュアルの翻訳に際して、顧客からUIデータが提供されることがあります。「UIを用語集として使用してほしい」という依頼が良くありますが、その依頼の仕方には注意が必要です。そもそもUIは画面の制約の中でユーザーに動作を理解してもらうためのものですが、用語集の目的は全く別のものだということはお分かりいただけると思います。
UIとは「ユーザーインタフェース」の略で、ソフトウェアの画面に表示されるボタンの名称であることがほとんどです。このソフトウェアのマニュアルを翻訳する場合には、ターゲット言語のUIデータを提供していただくか、ソフトウェアのデモ版のような形で、実画面を検証できるようにする必要があります。ここで大切なことは、UIは実際に画面に表示されている名称なので、マニュアルなどではその通りに表記する必要があるということです。
一方でUIには入力長の問題が発生します。表示できるのが4バイト(日本語は2バイトで一文字なので二文字分)しかない場合、6バイトの長さで訳してしまうとどういうことが発生するでしょうか。この場合、すべての文字が表示されず、文字切れを起こしてしまいます。そのため、本来なら半角スペースが挿入されるべき箇所のスペースが削除されていたり、用語集に登録されている内容とは全く違うことが発生したりしてしまうことがあるのです。
近年はブラウザで使用するWebアプリケーションが増えてきて、入力長の問題も以前と比べて少なくなってきているのは事実ですが、組込系ソフトウェアなどでは依然として入力長の制約は存在してしまいます。一例として、以前の連載で取り上げた用語を例としてとり上げましょう。
[Cost Sheet]は10バイトの入力長だとします。上記の例に基づくと、「原価シート」と訳すべきですから、ぴったり10バイトで問題はありません。
[Cost Sheet]→[原価シート] 〇
ところが現在新規用語として提案されている「コストシート」が承認されてしまった場合、12バイトとなり、文字切れします。
[Cost Sheet] →[コストシー] × 入力長オーバー
また、入力長が8バイトしかなかったとします。この場合は、原文が入力長に入りません。そのため原文は、例えば[CostSht]などとして翻訳されることになります。
省略する場合のルール決めは後述しますが、この場合は「原価シート」でも「コストシート」でも、どちらの訳語でも入力長をオーバーしてしまいます。
[Cost Sht]→[原価シート]×
[CostSht]→[コストシート]×
[CostSht]→[CostSht]△
[CostSht]→[原価Sht]△
そのため、今回は、用語集を無視してでも[原価Sht]を使用する必要があります。
または、UIの入力長を増やしてもらえるよう、開発者に依頼する必要があるでしょう。
そもそも目的や用途の異なるデータですから、その優先順位や用途の指示については、事前に詰めておく方が良いと言えます。
UIとマニュアルを同時に翻訳する場合には、両方の同期をとる必要がありますので、なおさら注意が必要です。
作業者にとって分かりやすい指示は、以下のようなものです。
- 明らかに画面上に表示されるテキスト/メッセージだとわかる場合にはUIデータを参照する
- UIデータと矛盾する場合にはQ&Aで問い合わせをする
- 画面上に表示されるUIかどうか判断ができない場合Q&Aで問い合わせをする
- それ以外は常に用語集が優先する
|
上記の1については、[UI] は角かっこで括るというルールを決めればある程度の作業効率は上がるような気がします。
ただし、当社の経験上、どんなにルールを定めても、開発者や文書作成者はルールを守ってくれるほど情報共有されていないということが大半です。
UIデータを用語集と一緒に渡すだけでは混乱する元だということが良くお判りいただけたのではないかと思います。
前述したUIテキストのうち、[CostSht]は、UIの入力長の問題でやむを得ず省略されています。前回のケースではUIデータが提供されていましたが、提供されていない場合に翻訳作業者はどう対応するでしょうか。[Cost Sht]だけでは、[Cost shift]なのか[Cost Sheet]なのかが判断できません。判断ができない場合に情報ソースとして活用できるのは、用語集の属性情報です。略語という属性をつけてフルテキストを一緒に入れておくこともメリットがあります。また、略語の案が浮かばないときや、なんの略語かがわからないようなときは、やはりQ&Aシートでやり取りすることが望ましいと言えます。
次回は、特別連載の最終回です。用語集ライフサイクルに関する管理方針の一案についてノウハウを共有します。