数千ページを超えるPDFファイルを
効率よく機械翻訳するコツ
~LDX hubを活用してプロセスを大幅改善~
言語(Language)のデジタル変革(DX)には、デジタルデータの変換や加工を支援する柔軟なソリューションが不可欠です。言語サービスの課題を解決するための豊富なAPI群を提供し、それらの自由な組み合わせをサポートする、当社のAPIサービス「LDX hub」では、1つのドキュメントの入力を起点に、さまざまな変換・加工処理と機械翻訳を連鎖させて、ニーズに応じた多種多様な出力を得ることができます。
本連載では、多言語化を必要とするさまざまなシーンにおいて、翻訳とコトバを変革するAPIサービス「LDX hub」を活用し、翻訳業務を効率化するポイントを解説します。今回のテーマは、PDFファイルの翻訳です。
PDFは、その使いやすさから、広く使用されている電子文書形式です。たとえば、こんなご経験はないでしょうか。
|
海外製の新しいシステムを導入したが、日本語版のユーザーマニュアルがなく、数千ページを超える英語のPDFファイルが提供された。 日本語版を欲しいと要求すると、高額な翻訳費用の見積書が送られてきた……。 |
AIの技術革新が日進月歩で進む時代ですから「こんな時こそ機械翻訳の出番」と思いきや、PDF化されたマニュアルの機械翻訳は、うまくいかないことがよくあります。その多くは、PDFから抽出したテキストに問題があります。
機械翻訳のプロセスでは、まず、ファイルの内容をテキストとして抽出し、次に、翻訳したい文章(ここでは「原文」と呼びます)のテキストを機械翻訳エンジンに入力する必要があります。PDFをうまく機械翻訳できない場合は、十中八九、PDFからテキストを抽出する際に、文中に不要な改行が挿入されてしまうことに起因しています。これはPDFの加工処理においてはよくあることなのですが、特に機械翻訳では大きな問題となります。
ほとんどの機械翻訳エンジンでは、改行を文の区切りとして認識しています。そのため、本来はない場所に改行が挿入されてしまうと、機械はそこで文が終了していると認識して翻訳をしてしまうのです。原文が想定とは違う箇所で切られているため、当然、翻訳の品質は低下します。
たとえば、当社の提供している機械翻訳エンジン「みんなの自動翻訳@KI」を使用してある一文の機械翻訳を実行すると、以下のように、そつなく翻訳してくれます。
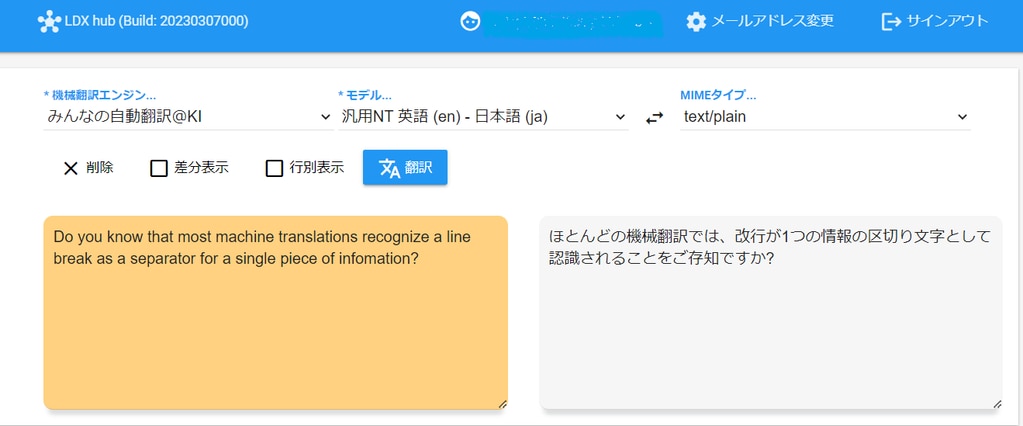
ところが、原文を以下のように改行すると訳文が変わります。
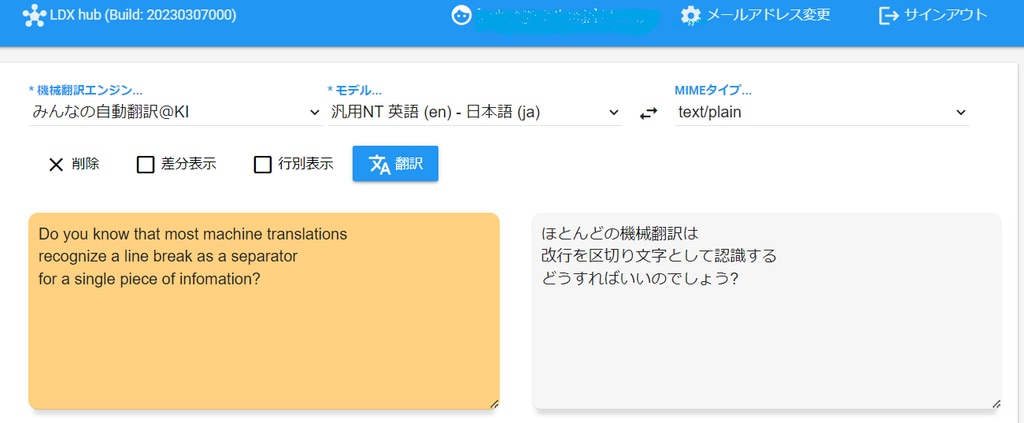
PDFから抽出したテキストを機械翻訳した場合に翻訳結果がおかしいときは、まずは原文に不要な改行が挿入されていないか疑ってみてください。
PDFのマニュアルには、図表が掲載されていることも多いでしょう。この図表データも、機械翻訳では、うまく翻訳されないことがあります。これには大きく分けて2つの理由があります。
|
1 については、できる限り再現性の高い文書コンバーターを選定するしかありませんが、2 については少し厄介です。
たとえば、とあるアプリケーションのユーザーインタフェース(UI)のテキストをLDX hubのサンプルアプリケーションで機械翻訳すると以下のような結果になります。
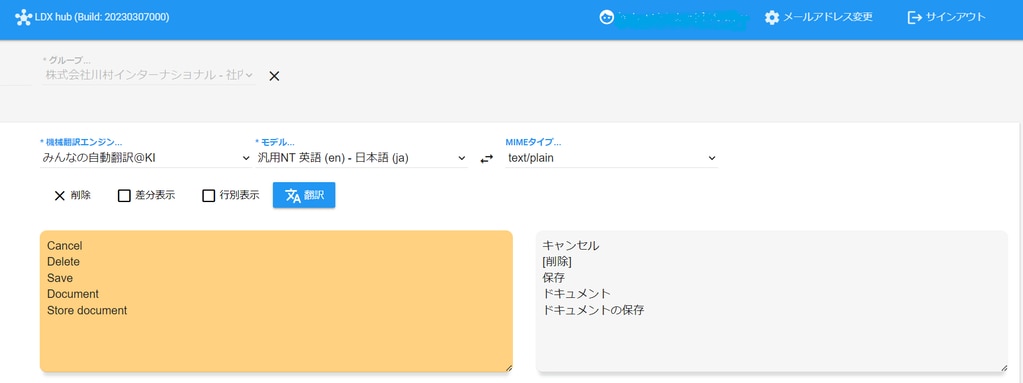
シンプルな単語ばかりですが、「Cancel」は「取消」かもしれませんし、「キャンセル」かもしれません。「Document」も「ドキュメント」や「文書」などの複数の訳語が考えられます。いずれも翻訳としては間違っているわけではありませんが、実際に使用される文脈に合った訳語が選ばれているかはわかりません。
一方、「Save」と「Store」がいずれも「保存」と訳されていることから、原文の単語による訳し分けもされていないことがわかります。さらに、「Delete」の訳語には原文にない角括弧が追加されていますが、他の訳語には追加されておらず、表記が統一されていません。
これらは前述したり、機械翻訳では1行単位で処理を実行していることに加え、AIが前後関係を考慮しないことに起因しています。個々の訳語が正しくても、1つのアプリケーション内で、原文の異なる用語に対して同じ訳語が使用されていたり、その逆に、同じ原文に対して異なる訳語や異なる表記が使用されていたりするとユーザーは混乱するため、翻訳としての品質は低いと言わざるを得ません。
同様のことが、単語の羅列であることの多い図表データの翻訳では発生しやすいと言えます。そのため、PDFに図表データが含まれている場合は、機械翻訳を行った後に、その部分を重点的に確認することをお勧めします。
次に、PDFファイルに含まれている画像はどう処理すべきでしょうか。スクリーンショットなどの画像化されたデータに含まれた文字は、バイナリデータの一部です。バイナリデータとは、0と1のみで表される二進数のデータです。
機械翻訳で処理するためにはテキストデータが必要となるため、画像の翻訳にはテキストを抽出する必要があります。バイナリデータからテキストを抽出するにはさまざまな方法が考えられますが、画像データに含まれているテキストは、Adobe社のIllustratorやPhotoshopなどのDTPアプリケーションを使用しないと加工できない可能性があります。また、スキャンデータの場合は、DTPアプリケーションを使ったとしても加工できないことがあり、そのような場合にはOCRソフトを利用する必要があります。
OCRとは、Optical Character Reader(またはRecognition)の略で、画像データのテキスト部分を認識して文字データに変換する光学文字認識機能のことを言います。身近な例でいうと、スキャナで紙文書を読み込み、書かれている文字をデジタル化する際にOCRは利用されています。
OCRを使用して機械翻訳を実施するには、以下の処理が必要になります。
|
これで画像の翻訳は可能となりますが、既知の問題として、OCRの精度自体は完璧ではないため、機械翻訳を行う前にテキストが正しく抽出できているかを確認することをお勧めします。これにより機械翻訳の精度が向上します。また、短い単語が多く出てくる画像では、図表の翻訳と同様に、訳文を重点的に確認することが望ましいです。
PDFの機械翻訳がうまくいかない場合、機械翻訳の精度の問題とは別に、そもそも原文の情報を正しく抽出できていない可能性があります。1000ページを超えるようなPDFファイルを効率よく機械翻訳するには、機械に任せるところは機械に任せつつ、エラーが起きやすいポイントを人が事前に理解して対処することが重要になります。エラーを防ぎ、効率よく品質・コスト・納期を最適化するために、人間が手を加えるポイントは以下の3つです。
|
これらの箇所を人の手で確認し、正しく修正を加えることで、機械翻訳したPDFファイルの品質は大幅に向上します。また、当然、不要な改行が入らないテキスト抽出/PDF変換ツールや高精度なOCRアプリケーションを活用すれば、人の手作業は削減できますが、こうしたツールやアプリケーションを別々に使用している限り、その間を何らかの形で人が仲介することになります。そのため、大幅な効率化を実現するには、こうした前処理と後処理のプロセスと機械翻訳とを連携させ、可能な限り自動化する何かが必要です。一連の工程を自動的に処理することができれば、作業の効率は大きく向上します。
今回取り上げたPDFファイルを機械翻訳するケースでは、LDX hubを活用することで、この自動化を実現できます。LDX hubでは、ユーザーが入力したデジタルデータに応じた変換・加工・機械翻訳などの処理と、その出力データ形式がすべて提示されるので、ユーザーは次に続く任意の処理を選択できるようになります。
また、出力データに対応する処理を繰り返すことにより、システムが保有する処理を自由に組み合わせて最終生成データを取得することができます。OCR処理後のテキストデータのみ、機械翻訳処理後のWordファイルなどのように、入出力後、翻訳・変換後の一連のプロセスで生成される中間データも活用できます。
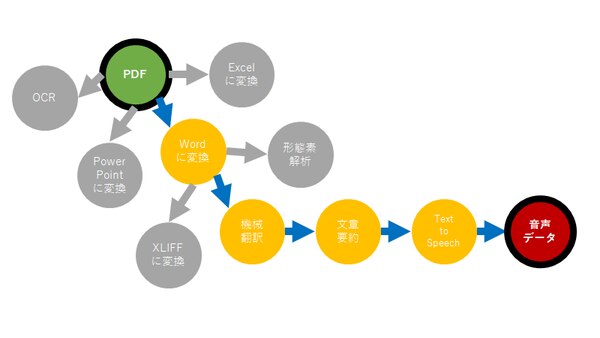
このようにLDX hubで利用可能なAPIは、2,000通り以上の処理の組み合わせが可能です。お客様の課題解決・活用/連携をサポートするための豊富なAPI群を安心して使えるAPIサービス、それがLDX hubです。



