
特許翻訳DXのススメ<明細書翻訳における機械翻訳活用方法>
「特許明細書の翻訳は機械翻訳では無理と聞きましたがやはりそうなんですか?」
あるお客様から、こんなご質問をいただきました。
もちろん、「いいえ、決してそんなことはありません」これが弊社の回答です。
原文自体が特殊な文体であり、また翻訳の要求品質や評価基準も他の技術文書と異なる特許明細書ですが、使い方次第では、充分に機械翻訳をご活用いただけます。
目次[非表示]
正確性、統一性が求められる特許翻訳
機械翻訳は、1950年代の「ルールベース(RBMT)」→1990年代の「統計ベース(SMT)」→現在の「ニューラル(NMT)」と進化を遂げました。
ニューラル機械翻訳では、旧タイプの機械翻訳エンジンでは考えられなかったほど、原文の理解力や訳文の流暢性が格段に向上しています。
ただし、下記のようなニューラル機械翻訳特有のエラーもあります。
- 文を超えた場合の訳語バラつき
- 文を超えた前後関係、結束性判断欠如
- 時制の判断エラー
- 数字の間違い
流暢性よりも正確性、統一性が求められる特許翻訳においては、上記エラーは致命的となります。場合によっては特許申請の拒絶理由とされる可能性も大いに考えられます。
AI翻訳の弱点をカバーする「翻訳メモリ」とは
「翻訳メモリ(TM=Translation Memory)」とは、まさにその名の通り「原文と訳文を対にして登録することができるデータベース」です。この「翻訳メモリ」は、ニューラル機械翻訳が出現する前から、人間が効率よく人手で翻訳をするために、プロ翻訳者の間では当たり前のごとく使用されているツールです。
翻訳済の特許明細書をデータベース化し自らの翻訳資産とすることで、一度翻訳した文章は二度と翻訳する必要はなくなり、またお客様側で継続して蓄積、活用すれば「品質安定化」と「コストカット」の両方が可能となります。
特許明細書においては、読み手に訴えかけるようなユニークな文章表現や多彩な言い回しは必要ではなく、これらはむしろタブーです。
文章ルールが統一化されており、また用語ブレは致命的なミスとなる特許翻訳において、翻訳メモリはまさにおあつらえ向きのツールなのです。
大量の特許文書を教師データとして完成した特許翻訳専用エンジン
『みんなの自動翻訳@KI 商用版』とは、国立研究開発法人情報通信研究機構(NICT)の開発による高性能エンジンを、セキュリティ面においてもご安心いただける仕様で「商用向け」とし弊社がサービス展開する機械翻訳エンジンです。
NICTと総務省が連携した取り組み「翻訳バンク」に集められた大量の翻訳データを教師データとしていますが、定期的に行われるアップデートにより性能は今なお向上し続けています。
特化型エンジンの一つである「特許エンジン」は、大量の特許明細書を用いて機械学習することで、特許明細書独特の文章表現に対する原文理解と訳文出力を可能としました。
公報の調査用としては勿論、出願用明細書の下訳としても充分にお使いいただける性能に仕上がっています。
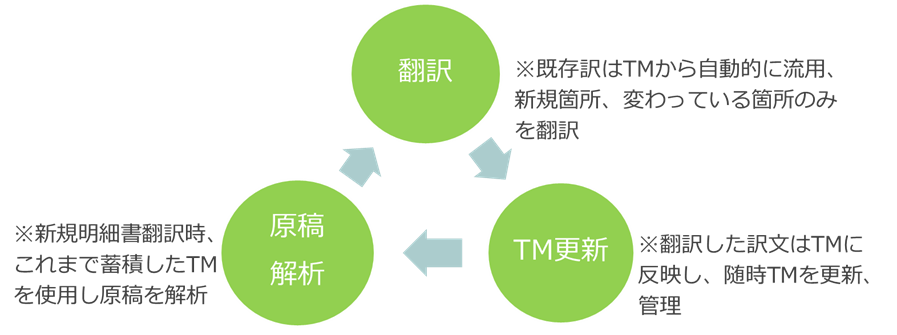
XMAT QUICK PE+みんなの自動翻訳を使用したオートメーションフロー
弊社の機械翻訳用プラットフォーム『XMAT』と機械翻訳エンジン『みんなの自動翻訳@KI商用版』連携による簡易フローを作成してみました。
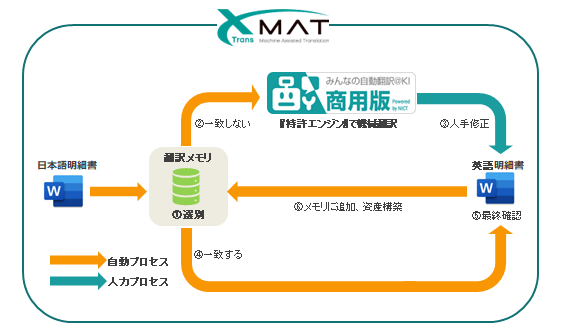
プラットフォーム上で機械翻訳にかける前にまず、
- 原稿の明細書内に翻訳メモリと一致する文があるかフィルタリングを行う、つまり「翻訳が必要な文とそうでない文の選別」を自動で行います。
- メモリと一致しない文は機械翻訳にかけ
- 必要に応じて人手で修正、
- メモリと一致する文はそのままメモリから訳文を流用、
- 最終的に②③で仕上がった文との前後関係を確認、微修正し、英語の明細書は完成です。
完成した明細書の翻訳文は⑥で更にメモリに追加され、次回以降の翻訳に有効利用することが可能となります。
このサイクルを何度も繰り返すことによりメモリは増え続け、ますますその恩恵を受けることができるのです。
機械翻訳活用の時代において、翻訳メモリは必須
企業知財部や特許事務所で特許翻訳をご担当されている方、あるいは翻訳外注の窓口をされている方で「機械翻訳の導入」をご検討される場合、その「機械翻訳エンジンが翻訳メモリと併用できる環境にあるか」をまず確認する必要があります。
明細書全体に対して単に機械翻訳をかけるだけでは、現状のAI翻訳の弱点である「文書間を超えた結束性欠如、統一性欠如」という点はカバーできず、出願用の翻訳においては大変な手直しが必要になります。
ただし翻訳メモリがあれば、その修正の手直しを劇的に減らすことができます。
また、翻訳メモリは上述した方法で「機械翻訳の性能を補う」事ができますが、更には「機械翻訳の性能を上げる」ことも可能です。
翻訳メモリは既に原文と訳文が対になっている状態ですので、機械学習用の教師データとして使用する事で、自社のお好み合った訳出表現が可能な「カスタムエンジン」を作り上げることができるのです。(カスタマイズの際はXMATのオプション機能「LAC」の追加ご契約が必要となります。)
機械翻訳導入を見越した人手の翻訳外注を
機械翻訳は、今すぐは必要ない、じっくり検討したい、というお客様もいらっしゃいます。
ただし、「翻訳会社に翻訳を外注して、ワードファイルを納品してもらいそれを確認、修正したものを保存しておく」この従来方式を繰り返しているだけでは、いざとなった時の機械翻訳の有効活用はできません。
なぜならそのサイクルに「お客様側での翻訳メモリ構築、資産化」は見出せないからです。
川村インターナショナルでは特許翻訳限定の付加価値サービスとして、訳文の明細書ワードファイルと併せて、翻訳メモリも納品しています。
お客様側で資産となった翻訳メモリが人手翻訳の外注の際の「品質安定化とコストカット」に効果を発揮するのはもちろんですが、お客様は「翻訳外注をしながら将来の機械翻訳導入に備える」ことも可能なのです。
おわりに
最後までお読みいただきましてありがとうございました。
XMATのオプション機能「LAC」でのエンジンカスタマイズ、追加学習(アダプテーション)については、弊社にて開催の無料オンラインセミナーにて詳しいご説明をさせていただいております。
皆様にとって有用な情報となれば幸いです。
関連記事




